This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
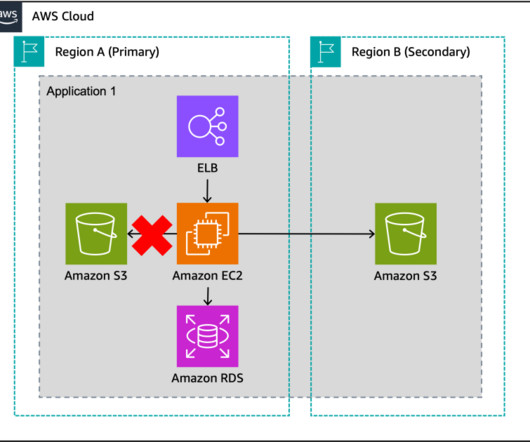
This allows you to build multi-Region applications and leverage a spectrum of approaches from backup and restore to pilot light to active/active to implement your multi-Region architecture. The component-level failover strategy helps you recover from individual component impairments.
Automating DisasterRecovery for Pure Storage FlashArray and Pure Cloud Block Store with JetStream DR by Pure Storage Blog Summary Cloud-based disasterrecovery can offer many advantages for organizations. Customers only pay for resources when needed, such as during a failover or DR testing.
Welcome to the third post of a multi-part series that addresses disasterrecovery (DR) strategies with the use of AWS-managed services to align with customer requirements of performance, cost, and compliance. The post also introduces a multi-site active/passive approach.
Ultimately, any event that prevents a workload or system from fulfilling its business objectives in its primary location is classified a disaster. This blog post shows how to architect for disasterrecovery (DR) , which is the process of preparing for and recovering from a disaster. DR objectives.
In an era where cyber threats are constantly evolving, understanding the differences between cyber recovery, disasterrecovery (DR) , and backup & recovery is critical to ensuring an organization’s resilience and security. DisasterRecovery vs. Backup Disasterrecovery encompasses a broader approach than backup alone.
In a previous blog post on business continuity and disasterrecovery (DR), we shared how the City of New Orleans adopted ActiveDR™ for their DR requirements and realized impactful business results through its simplicity and innovation. But disasterrecovery doesn’t need to be a complicated use case.
Understanding the Evolution of Ransomware Attacks Traditional ransomware attacks focused on encrypting active production data the information businesses use daily in their operations or, live data, such as customer databases, financial records, and email systems. Automated Recovery Testing Gone are the days of manual backup testing.
In my first blog post of this series , I introduced you to four strategies for disasterrecovery (DR). My subsequent posts shared details on the backup and restore , pilot light, and warm standby active/passive strategies. DR strategies: Multi-site active/active. Implementing multi-site active/active.
Since the primary objective of a backup site is disasterrecovery (DR) management, this site is often referred to as a DR site. DisasterRecovery on AWS. DR strategy defines the recovery objectives for downtime and data loss. The workload has a recovery time objective (RTO) and a recovery point objective (RPO).
In part I of this series, we introduced a disasterrecovery (DR) concept that uses managed services through a single AWS Region strategy. Health checks are necessary for configuring DNS failover within Route 53. DisasterRecovery with AWS Managed Services, Part I: Single Region. Other posts in this series.
Solutions Review’s listing of the best backup and disasterrecovery companies is an annual sneak peek of the solution providers included in our Buyer’s Guide and Solutions Directory. These changes speak to the cloud’s continued rise, significantly impacting the backup and disasterrecovery market over recent years.
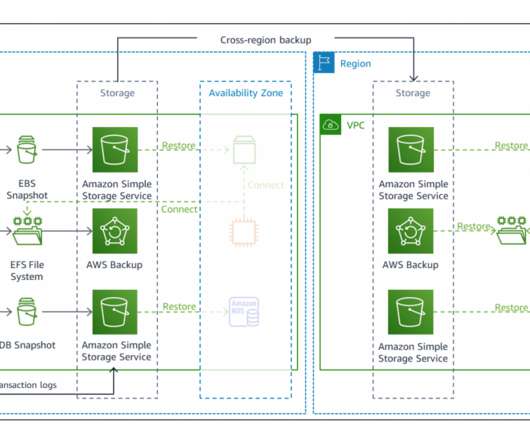
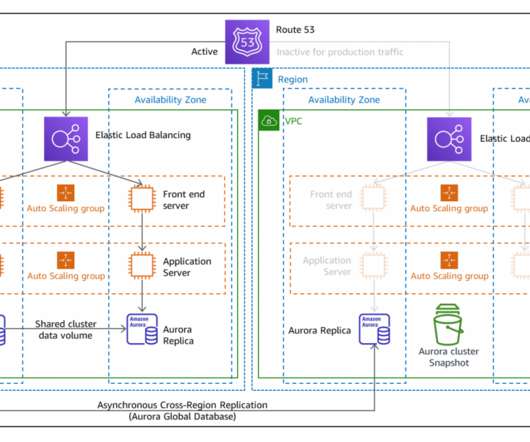
In this blog post, we share a reference architecture that uses a multi-Region active/passive strategy to implement a hot standby strategy for disasterrecovery (DR). With the multi-Region active/passive strategy, your workloads operate in primary and secondary Regions with full capacity. Figure 1. Amazon RDS database.
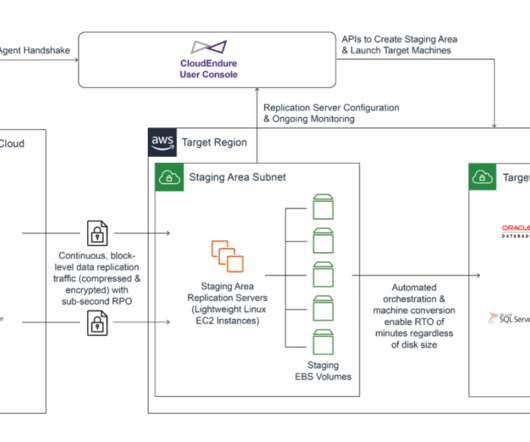
When designing a DisasterRecovery plan, one of the main questions we are asked is how Microsoft Active Directory will be handled during a test or failover scenario. You can instruct CloudEndure DisasterRecovery to automatically launch thousands of your machines in their fully provisioned state in minutes.
This is ideal for those that require a recovery point objective (RPO) of seconds. Through recovery operations such journal file-level restores (JFLR), move, failover test & live failover, Zerto can restore an application to a point in time prior to infection. Get Your Files Back! Avoid Sneaky Infrastructure Meltdowns.
Failover vs. Failback: What’s the Difference? by Pure Storage Blog A key distinction in the realm of disasterrecovery is the one between failover and failback. Both play critical roles in business continuity and disasterrecovery efforts, so it’s important to understand what they are and why they’re different.
Failover vs. Failback: What’s the Difference? by Pure Storage Blog A key distinction in the realm of disasterrecovery is the one between failover and failback. Both play critical roles in business continuity and disasterrecovery efforts, so it’s important to understand what they are and why they’re different.
In a previous blog post , I introduced you to four strategies for disasterrecovery (DR) on AWS. These strategies enable you to prepare for and recover from a disaster. For your recovery Region, you should use a different AWS account than your primary Region, with different credentials.
In this blog post, you will learn about two more active/passive strategies that enable your workload to recover from disaster events such as natural disasters, technical failures, or human actions. Previously, I introduced you to four strategies for disasterrecovery (DR) on AWS. Pilot light DR strategy.
Most SAP HANA customers today are using SAP HANA system replication (HSR) to ensure the high availability and disasterrecovery systems remain in sync. It’s easy to set up and usually the SAP application or SAP BASIS team does the configuration and controls the failovers. . These writes are continuous, not synchronous.
In the challenging landscape of keeping your IT operations online all the time, understanding the contrasting methodologies of high availability (HA) and disasterrecovery (DR) is paramount. There are two types of HA clustering configurations that are used to host an application: active-passive and active-active.
This article will explain in detail the functionality of one-to-many replication, how it employs virtual replication appliances and groups, and some common recovery models that leverage its features. Zerto, a Hewlett Packard Enterprise company, is a disasterrecovery (DR) solution that offers a unique one-to-many replication feature.
In this submission, JetStream Software ‘s President and Co-Founder Rich Petersen makes the case for why organizations should shift to disasterrecovery as a cloud-based service right now. are already defined and available before the cluster is needed for failover.
These events could be man-made (industrial sabotage, cyber-attacks, workplace violence) or natural disasters (pandemics, hurricanes, floods), etc. Business Continuity Plan vs. DisasterRecovery Plan. Instructions about how to use the plan end-to-end, from activation to de-activation phases.
Here are comprehensive solutions you can utilize to achieve data redundancy and ensure effective disasterrecovery: Cloud storage solutions Cloud storage platforms such as Amazon Web Services, Microsoft Azure, or Google Cloud employ advanced data replication techniques and store data across multiple servers and locations.
In fact, according to a survey by Evolve IP , 93% of companies that lost their data for 10 days or more filed for bankruptcy within one year of the disaster. For that reason and others, it’s critical that you have a disasterrecovery plan for your organization. DisasterRecovery Is a Non-negotiable.
With more than three million consumer households at stake, they have designated disaster preparedness a ‘mission critical’ program. Periodic testing and validation of their documented DisasterRecovery Plans are the only way to certify their DR Program as credible and viable. The scale of these annual tests can vary.
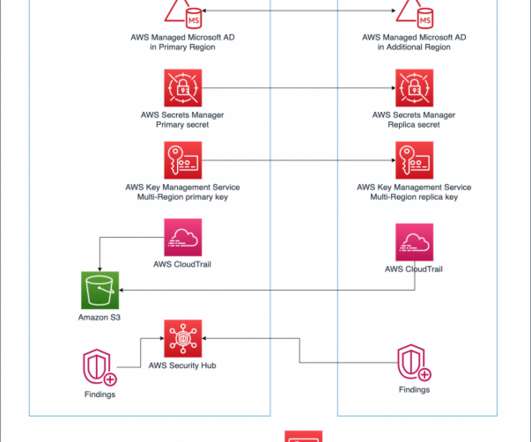
Reducing Recovery Point Objectives (RPO) and Recovery Time Objectives (RTO) as part of disasterrecovery (DR) plan. For workloads that use directory services, the AWS Directory Service for Microsoft Active Directory Enterprise Edition can be set up to automatically replicate directory data across Regions.
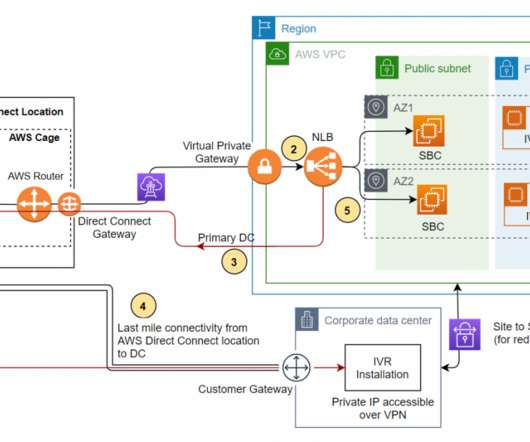
The biggest advantage of VPN is that it’s easy to implement and many solutions work directly with Active Directory or LDAP. After users authenticate with the VPN system, they’re allowed to access any area of the network provided the user is a part of an authorized group. Secondary verification can be integrated with VPN including ZTNA.
Though the work seemingly touches all parts of the business, you’re oftentimes focused on a parallel track of activity that isn’t normally top of mind with your business partners. She carries an MBCP and AFBCI certification, as well as is an active member of her local ACP. Business Continuity can sometimes be a lonely road.
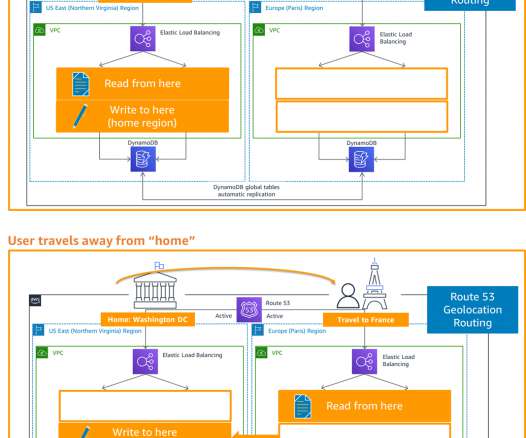
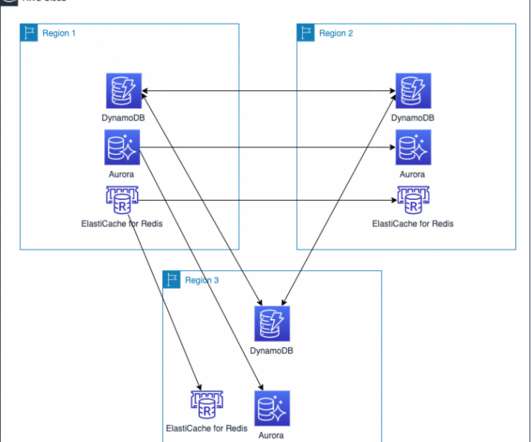
Failover routing is also automatically handled if the connectivity or availability to a bucket changes. A DynamoDB global table is the only AWS managed offering that allows for multiple active writers in a multi-Region topology (active-active and multi-Region). DisasterRecovery Architecture on AWS blog series.
In 2022, IDC conducted a study to understand the evolving requirements for ransomware and disasterrecovery preparation. The IDC study found that 79% of those surveyed activated a disaster response, 83% experienced data corruption from an attack, and nearly 60% experienced unrecoverable data.
In that event, businesses require a disasterrecovery plan with best practices to restore hardware, applications, and data in time to meet the business recovery needs. What is a DisasterRecovery Plan? Notable Best Practices for DisasterRecovery. Why Do I Need One?
Organizations are using Pure Cloud Block Store for: Disasterrecovery : Cloud economics, automation, data replication, and recovery orchestration have made disasterrecovery (DR) to the cloud ideal, especially if you’re operating from a single physical site.
The data services provided with any Pure Cloud Block Store instance can be used for a number of use cases with Microsoft SQL Server: Data protection and disasterrecovery: Replicated or offloaded volume snapshots or continuous replication using ActiveDR™ can be implemented for database volumes. . Cost-effective DisasterRecovery .
The only effective response is a disasterrecovery solution that can bring the data and the operations it enables back online as quickly as possible and with the least amount of data loss. Local systems and backups can be compromised, making remote recovery the only option left.
SREs can set up customer service-level agreements (SLAs) that will trigger when prompted during a disruption, automating the recovery and bringing the application back online. This eliminates the need for manual intervention and reduces the risk of human error when initiating a failover.
The last few months he has been heavily involved with a historic pandemic response at Texas Children’s which involved a 140+ day activation of their incident command system. 26:28min- The role of his BC program in non-traditional activities like COVID. Key Points: 0:28min- James’ background. 22:47min- Is he lucky? Links: LinkedIn .
The threat of ransomware was definitely on the mind of one Zerto user who explained, “ We use Zerto to protect our staff information against ransomware , and [it] is outlined in our disasterrecovery plan.” It also allowed us to preconfigure the boot sequence for a failover test or actual recovery.”
It combines the best-in-class hardware and disasterrecovery software, which includes HPE Alletra, HPE ProLiant, and Zerto for data protection. Leverage the built-in features of Zerto Recovery Reports used during live and test failovers as well as Zerto Analytics to prove Service Level Agreements (SLAs) for auditing and compliance.
DXC Technology: Turning Ideas into Real Business Impact by Blog Home Summary When this leading technology services provider needed a robust disasterrecovery (DR) solution for its Managed Container Services platform, DXC Technology chose Portworx by Pure Storage.
The question is, how will you ensure that any updates to your SQL database are captured not only in the active operational database but also in the secondary instances of the database residing in the backup AZs? In normal circumstances, the active SQL Server cluster node will reside in the same AZ as the primary storage node.
Data protection is a broad field, encompassing backup and disasterrecovery, data storage, business continuity, cybersecurity, endpoint management, data privacy, and data loss prevention. Acronis offers backup, disasterrecovery, and secure file sync and share solutions. Note: Companies are listed in alphabetical order.
Many data centers incorporate High Availability – redundancy, hardening, segregated graceful failover – and assume that because “It Can Never Fail” there is no need for DisasterRecovery or Business Continuity. Why didn’t they activate their DisasterRecovery Plan?
Also, HDDs can hold more data currently, so they’re preferred for long-term storage with fewer reads, such as storage reservoirs for disasterrecovery and backups. Every write action causes degradation on the drive, so it will eventually fail, making it important to have failover and backups. Which Is Better: SSD or HDD?
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.











































Let's personalize your content