This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
I think with cyber threats and power outages being the focus of the moment, occupying us business continuity folks, we have forgotten about a good old threat: the computer outage. There is very little spare capacity in the system to accommodate delayed passengers and cancelled flights, so the effects take days to sort out.
The capacity listed for each model is effective capacity with a 4:1 data reduction rate. . Higher availability: Synchronous replication can be implemented between two Pure Cloud Block Store instances to ensure that, in the event of an availability zone outage, the storage remains accessible to SQL Server. .
Doing this work is one of the most productive activities a BC professional can undertake. Capacity limitations. We often see that efforts to recover critical apps are derailed by limitations in computing or storage capacity. In today’s environment, you cannot just go out and buy capacity. Having these items is not enough.
As a result, businesses were on an ever-revolving turntable of purchasing new arrays, installing them, migrating data, juggling weekend outages, and managing months-long implementations. For our early customers, it has meant a decade without the hassles of migrations, storage refreshes, weekend outages, or application outages.
Remember, after an outage, every minute counts…. Pure SafeMode is a built-in feature of the Purity Operating Environment that prevents data from being manually deleted before the policy/timer expires, allowing you to recover quickly in the event of a mistake or malicious activity.
If we don’t meet the performance or capacity obligations, we proactively ship more storage arrays and set them up at no cost to you. This is because Pure Storage® is committing to a performance and capacity obligation. Pure’s Capacity Management Guarantee . We’re clear about our obligation in our product guide.
Using multiple Regions ensures resiliency in the most serious, widespread outages. This is because Amazon EC2 Auto Scaling groups automatically replace any terminated or failed nodes, which ensures that the cluster always has the capacity to run your workload. DR Strategies. Implementing the multi-Region/backup and restore strategy.
Service outages ultimately frustrate customers, leading to churn and loss of trust. Continuously monitor system logs to detect unusual activity, such as failed login attempts or unauthorized data transfers. Endpoint detection and response tools monitor and respond to suspicious activities on devices within the network.
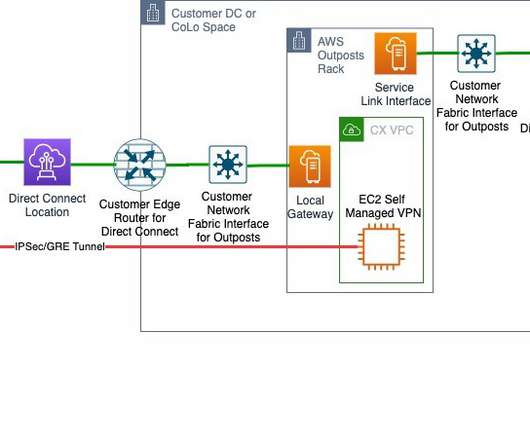
Therefore, if you’re designing a DR strategy to withstand events such as power outages, flooding, and other other localized disruptions, then using a Multi-AZ DR strategy within an AWS Region can provide the protection you need. Active/passive and active/active DR strategies. In Figure 3, we show how active/passive works.
Instructions about how to use the plan end-to-end, from activation to de-activation phases. Since most businesses today are heavily IT reliant, DRP tends to focus on business data and information systems by addressing one or several points of failure including application downtime, network outages, hardware failure, data loss, etc.
CIOs can use the capacity required immediately via OPEX, manage costs over time based upon discounting, and have the ability to burst into the type of high IO (a.k.a. It’s simple to activate snapshots and set up replication, which can help you facilitate quick recovery in the event of a system failure or data loss. .
BCM (business continuity management) is a form of risk management that deals with the threat of business activities or processes being interrupted. The Hampshire warehouse was responsible for 10% of the company’s service, but the organisation will no doubt be looking at how to increase capacity from its other warehouses.
In today’s post we’ll look at why organizations still need to be adept at IT disaster recovery (IT/DR) and describe the four phases of restoring IT services after an outage. Phase 1: Preparation Technically, preparation is not a phase of disaster recovery since it happens before the outage. Estimate how long the outage will last.
Global IT disruptions and outages are becoming the new normal, testing the operational resilience of businesses everywhere. For instance, if an outage occurs, having a unified view can help teams quickly identify and resolve issues, minimizing the impact on customer experience. Take the product tour.
If you’re using infrastructure as a service (IaaS), constantly check and monitor your configurations, and be sure to employ the same monitoring of suspicious activity as you do on-prem. . If you have, for example, tens of thousands of options for configurations, no one will be able to be an expert on all of them.
The manufacturing processes they support—like the aluminum casting required to produce powertrain and engine components—are energy-intensive and prone to outages. With Pure Evergreen//Forever ™, Nissan Australia can continuously scale its capacity and upgrade its arrays with zero disruption to its operations. “I
This is particularly useful for disaster recovery, enabling rapid spin-up of infrastructure in response to an outage or disaster. This means that if you want to increase your storage capacity, you have to add more nodes (bare metal servers) into the cluster. AVS is hyperconverged infrastructure built on top of Azure bare metal servers.
Global IT disruptions and outages are becoming the new normal, testing the operational resilience of businesses everywhere. For instance, if an outage occurs, having a unified view can help teams quickly identify and resolve issues, minimizing the impact on customer experience. Take the product tour.
Since then, so much more value has been added to our all-flash platform with innovative releases such as ActiveCluster ™ (active-active synchronous replication), FlashArray//X ™ (the first enterprise-class all-NVMe FlashArray™), ActiveDR ™ continuous replication , and FlashArray//XL ™. By 2025, approximately 1.2
ZenGRC is a compliance software that may help simplify and streamline your compliance processes by automating various time-consuming, manual activities. Data processing must be quick, accurate, valid, and allowed. As a result, planning ahead of time for a more efficient approach can save time and money.
ZenGRC is a compliance software that may help simplify and streamline your compliance processes by automating various time-consuming, manual activities. Data processing must be quick, accurate, valid, and allowed. As a result, planning ahead of time for a more efficient approach can save time and money.
Recovering your mission-critical workloads from outages is essential for business continuity and providing services to customers with little or no interruption. Depending on the RPO and RTO of the mission-critical workload, the requirement for disaster recovery ranges from simple backup and restore, to multi-site, active-active, setup.
To recognize its importance, you only need to look at the multibillion-dollar industry that has been built up around it or read the news to observe the near-daily outages of major businesses or ransoms paid to bad actors. Once SafeMode has been activated for a protection group, the only way to turn it off is to contact Pure Support.
Volume snapshots are always thin-provisioned, deduplicated, compressed, and require no snapshot capacity reservations. ActiveCluster also lets admins configure zero RPOs and recovery time objectives (RTOs) between two FlashArray environments with active/active bi-directional synchronous replication and transparent failover.
2, 4, or 8 controllers) Since all controllers in all nodes are active, if a controller fails the performance impact is proportional to the number of controllers (i.e. 2, 4, or 8 controllers) Since all controllers in all nodes are active, if a controller fails the performance impact is proportional to the number of controllers (i.e.
For instance, provisioning infrastructure resources, managing server configurations, or deploying code updates can be automated, allowing teams to focus on higher-value activities like innovation, problem-solving, and strategic planning. This acceleration of processes leads to faster time to market for products and services.
The pain is felt by the healthcare organization when a vendor has an outage because of ransomware or another cybersecurity intrusion. The program includes numerous activities that work together to strengthen their security posture. Vendor Due Diligence. Healthcare organizations must perform due diligence on all vendors.
The fire and impact: The fire OVHcloud had in their data centre campus in Strasburg, reminds us, that just because we have put our applications in place or have bought software that is hosted in the cloud, we are still vulnerable to IT outages. The fire took six hours to put out which shows how substantial it was!
The fire and impact: The fire OVHcloud had in their data centre campus in Strasburg, reminds us, that just because we have put our applications in place or have bought software that is hosted in the cloud, we are still vulnerable to IT outages. The fire took six hours to put out which shows how substantial it was!
Mitigating supply chain risk After widespread coverage, the CrowdStrike outage from 19 July 2024 hardly needs an introduction. The outage was caused by a bad security update rolled out by CrowdStrike. Without question, this is one of the most expensive IT outages to date, with significant global impact. million Windows devices.
This provides end-to-end performance, capacity, and feature management/insights. Active-active stretched cluster vVol support with VMware and Pure Storage. Together, Portworx + vVols focuses on what matters; not the VM, but the application and the persistent volume used by an application. Ransomware protection .
Activate your business continuity plan. Monitor your roof’s snow load to ensure it does not exceed its maximum capacity. In case of a power outage, use your generator. Designate times for key staff members to call into conference calls for situation overviews. After a winter event. Vintage color tone style.
More uptime means more donations on this critical day, as well as the ability to focus on delivering great digital experiences as opposed to remediating outages. With significant increases in traffic and donor activity, you’ll want to be sure your website and digital operations are ready for the load. Back-end systems.
In 2024, it will be crucial to optimize the transparency afforded by these regulations, and by dragging cybercriminals out into the open, authorities can more effectively curtail their illicit activity.” If the AI detects unusual activity, it can respond autonomously to increase their level of protection.
Data program must-have: High-capacity storage that can scale and consolidate both structured data and unstructured sensor data. If security events and outages can cause enterprises to come to a grinding halt—what about a city that’s running on data? billion by 2026. Creating Digital Twins. How to Address Smart City Data Risks.
Persistence detection: This introduces capabilities to assess data in storage systems for active or latent threats, as well as providing the ability to restore known copies of your data, nearly instantly. These questions are asked by SIEM class systems to determine if an attack is in progress.
The BCM program contains three distinct implementation phases; its activities are outlined in the table below. The BCM program contains three distinct implementation phases; its activities are outlined in the table below. This is why Business Continuity Management (BCM) is a program and not a project.
The BCM program contains three distinct implementation phases; its activities are outlined in the table below. The BCM program contains three distinct implementation phases; its activities are outlined in the table below. ARTICLE SECTIONS. 1 – Introduction to BCP. 2 – BCM Program Implementation. 3 – Risk Assessment.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.










































Let's personalize your content