This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Customers only pay for resources when needed, such as during a failover or DR testing. Automation and orchestration: Many cloud-based DR solutions offer automated failover and failback, reducing downtime and simplifying disaster recovery processes. This is a cost-effective solution but with a higher recovery time objective (RTO).
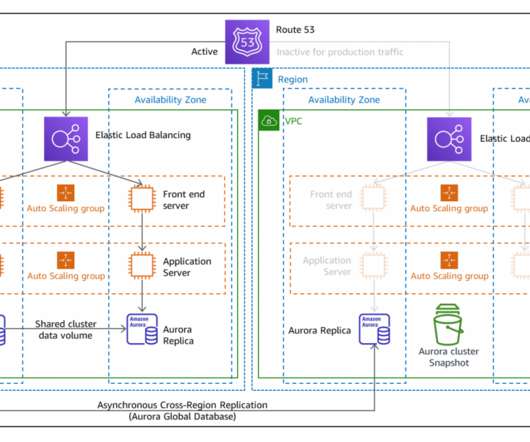
Active/passive and active/active DR strategies. Active/passive DR. Figure 2 categorizes DR strategies as either active/passive or active/active. In Figure 3, we show how active/passive works. All requests are now switched to be routed there in a process called “failover.”
HDD devices are slower, but they have a large storage capacity. Even with the higher speed capacity, an SSD has its disadvantages over an HDD, depending on your application. Traditionally, the biggest disadvantages of an SSD have been price, degradation, and capacity. SSD devices are faster, but they also cost more.
I use these examples to illustrate the huge difference between a simple active-passive database running on two servers and a scalable cloud-native database that gets lost when you describe a system merely as “shared-nothing.” And with Pure Storage’s shared-NVRAM approach, this makes controller failover events completely non-disruptive.
Resource Balancer only uses capacity-free space to determine where to place the new volume.¹³ This is why PowerStore can support different models with different capacities in the same “cluster,” because data is located only on one appliance at a time. Item #3: “ Active/Active Controller Architecture”¹⁴ Is a Good Thing We see this B.S.
In the cloud, everything is thick provisioned and you pay separately for capacity and performance. Controller 1 is actively using those resources while controller 2 is in a standby configuration. You can update the software on controller 2, then failover so that it’s active.
The capacity listed for each model is effective capacity with a 4:1 data reduction rate. . Pure Cloud Block Store provides the following benefits to SQL Server instances that utilize its volumes for database files: A reduction in cost for cross availability zone/region traffic and capacity consumption.
In this blog post, we share a reference architecture that uses a multi-Region active/passive strategy to implement a hot standby strategy for disaster recovery (DR). With the multi-Region active/passive strategy, your workloads operate in primary and secondary Regions with full capacity. This keeps RTO and RPO low.
In this blog post, you will learn about two more active/passive strategies that enable your workload to recover from disaster events such as natural disasters, technical failures, or human actions. These are both active/passive strategies (see the “Active/passive and active/active DR strategies” section in my previous post).
Health checks are necessary for configuring DNS failover within Route 53. Once an application or resource becomes unhealthy, you’ll need to initiate a manual failover process to create resources in the secondary Region. Route 53 health checks monitor the health and performance of your web applications, web servers, and other resources.
Instructions about how to use the plan end-to-end, from activation to de-activation phases. The DRP assumes that a disaster has disrupted your organization’s IT operations and/or infrastructure, and that certain measures need to be activated to return to normal operating conditions in the shortest possible time.
During failover, scale up resources and increase traffic to the Region. This pattern works well for applications that must respond quickly but don’t need immediate full capacity. Active-active (Tier 1). Now that you’ve set up a DR site in a second AWS Region, how do you route traffic to it if there’s a failover?
If you’re using infrastructure as a service (IaaS), constantly check and monitor your configurations, and be sure to employ the same monitoring of suspicious activity as you do on-prem. . PX-Backup can continually sync two FlashBlade appliances at two different data centers for immediate failover.
Volume snapshots are always thin-provisioned, deduplicated, compressed, and require no snapshot capacity reservations. Single-command failover. To minimize risk, orchestration steps for the entire environment stay the same during the test or in an actual failover event. Active/active clustered array pairs.
To counteract this challenge, Nissan Australia runs its manufacturing workloads on VMware in an active-active configuration across two data centers that leverage Pure Storage® FlashArray//X ™ with ActiveCluster ™ for seamless failovers. What’s more, they had to pay for two systems concurrently during those crossover periods.
When most storage vendors talk about non-disruptive upgrade (NDU) they’re focusing on software upgrades, or adding storage capacity to an existing storage array. Pairing the FlashArray’s architecture with the Purity operating environment, which handles dynamic controller failovers, allows the controllers to be completely transparent.
The criticality of these synergies becomes obvious when we recognize analytics as the products (the outputs and deliverables) of the data science and machine learning activities that are applied to enterprise data (the inputs). In addition to low latency, there are also other system features (i.e.,
More complex systems requiring better performance and storage capacity might be better using the ZFS file system. Using Btrfs, administrators can offer fault tolerance and failover should a copy of a saved file get corrupted. Btrfs and ZFS are the two main systems to choose from when you partition your disks. What Is Btrfs?
Moreover, the ability to scale storage on demand ensures it can migrate and modernize its legacy systems quickly while reducing storage costs, both in terms of capacity and upgrades. Failover processes became a priority for the bank after one team had to manually fail over 4,000 virtual machines in a single weekend.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.


























Let's personalize your content