This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Most organizations believe they’re prepared for ransomware attacks with a simple strategy: maintain good backups and use them to restore systems if cybercriminals encrypt their data. Recent research from IDC reveals that in 2023, more than half of all ransomware attacks included attempts to compromise backup systems.
This allows you to build multi-Region applications and leverage a spectrum of approaches from backup and restore to pilot light to active/active to implement your multi-Region architecture. The component-level failover strategy helps you recover from individual component impairments.
In an era where cyber threats are constantly evolving, understanding the differences between cyber recovery, disaster recovery (DR) , and backup & recovery is critical to ensuring an organization’s resilience and security. While backups are a critical component of both cyber recovery and DR, they are reactive by nature.
In part two of this series, we introduced a DR concept that utilizes managed services through a backup and restore strategy with multiple Regions. The post also introduces a multi-site active/passive approach. You would just need to create the records and specify failover for the routing policy.
In part two, we introduce a multi-Region backup and restore approach. Using a backup and restore strategy will safeguard applications and data against large-scale events as a cost-effective solution, but will result in longer downtimes and greater loss of data in the event of a disaster as compared to other strategies as shown in Figure 1.
Solutions Review’s Tim King compiled this roundup of 45 World Backup Day quotes from 32 experts for 2023, part of our ongoing coverage of the enterprise storage and data protection market. World Backup Day quotes have been vetted for relevance and ability to add business value.
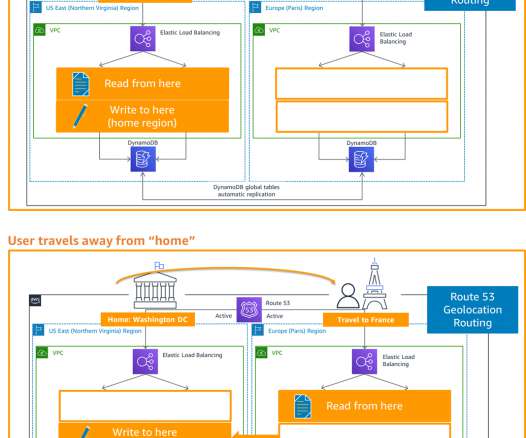
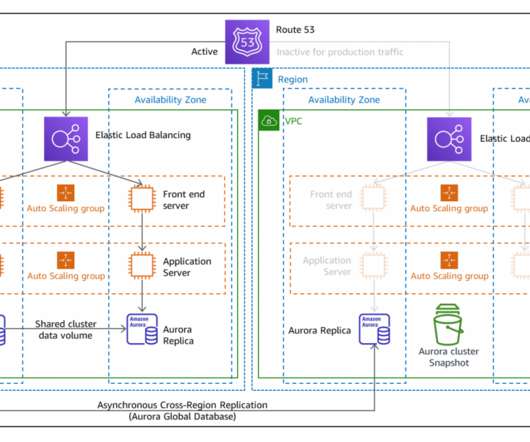
Active/passive and active/active DR strategies. Active/passive DR. Figure 2 categorizes DR strategies as either active/passive or active/active. In Figure 3, we show how active/passive works. All requests are now switched to be routed there in a process called “failover.”
Solutions Review’s listing of the best backup and disaster recovery companies is an annual sneak peek of the solution providers included in our Buyer’s Guide and Solutions Directory. Though backup practices have existed for years, there have been major changes and challenges in the space over the last two years.
My subsequent posts shared details on the backup and restore , pilot light, and warm standby active/passive strategies. In this post, you’ll learn how to implement an active/active strategy to run your workload and serve requests in two or more distinct sites. DR strategies: Multi-site active/active.
Through recovery operations such journal file-level restores (JFLR), move, failover test & live failover, Zerto can restore an application to a point in time prior to infection. New Backup & Restore Functionality in Zerto 9.5: Instant File Restore for Linux. Get Your Files Back! Avoid Sneaky Infrastructure Meltdowns.
Failover vs. Failback: What’s the Difference? by Pure Storage Blog A key distinction in the realm of disaster recovery is the one between failover and failback. In this article, we’ll develop a baseline understanding of what failover and failback are. What Is Failover? Their effects, however, couldn’t be more different.
Failover vs. Failback: What’s the Difference? by Pure Storage Blog A key distinction in the realm of disaster recovery is the one between failover and failback. In this article, we’ll develop a baseline understanding of what failover and failback are. What Is Failover? Their effects, however, couldn’t be more different.
DR strategies: Choosing backup and restore. As shown in Figure 1, backup and restore is associated with higher RTO (recovery time objective) and RPO (recovery point objective). However, backup and restore can still be the right strategy for your workload because it is the easiest and least expensive strategy to implement.
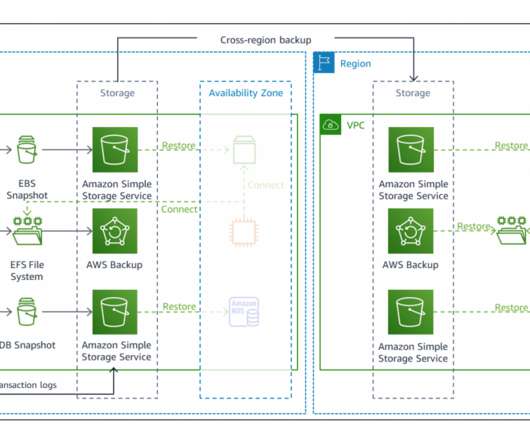
Failover routing is also automatically handled if the connectivity or availability to a bucket changes. Copying backups. Scheduled backups can be set up with AWS Backup , which automates backups of your data to meet business requirements. Backup copy times will vary depending on size and change rates.
These eight benefits assist not just in recovering from a ransomware attack, but also in hardening systems and backups to prepare for and prevent ransomware attacks. Local systems and backups can be compromised, making remote recovery the only option left. More copies across recovery sites mean more recovery options when needed.
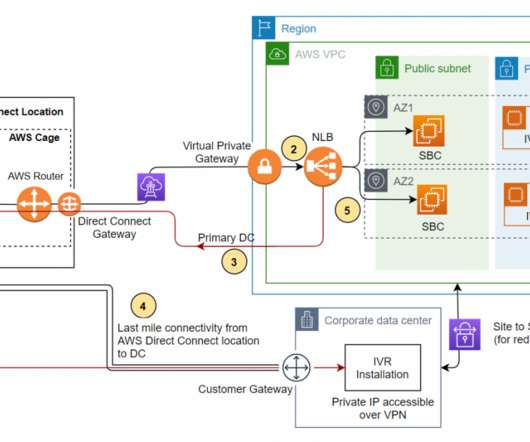
We address a scenario in which you are mandated to host the workload on a corporate data center (DC), and configure the backup site on Amazon Web Services (AWS). Since the primary objective of a backup site is disaster recovery (DR) management, this site is often referred to as a DR site. Disaster Recovery on AWS. Conclusion.
SSDs aren’t typically used for long-term backups, so they’re built for both but are typically used in speed-driven applications. Also, HDDs can hold more data currently, so they’re preferred for long-term storage with fewer reads, such as storage reservoirs for disaster recovery and backups. Does SSD Read Faster than HDD?
The importance of off-site data backup, or the practice of storing data in a remote or an external location, cannot be overstated. If you’re looking for ways to improve the off-site backup strategy of your business in New Jersey, leverage the following solutions.
Backup and disaster recovery are critical elements in the drive to thwart ransomware. Backup is the final layer of data protection. All too often, however, organizations mount what they think are effective backup systems only to find them inadequate in a real emergency. Three Key Elements.
So if you haven't already, it's time you prioritize data backup as a vital component of your business continuity strategy. Data backup refers to the creation of copies of data to ensure it is not lost, corrupted, or destroyed in the event of a disaster or other unforeseen circumstance. How does data backup support business continuity?
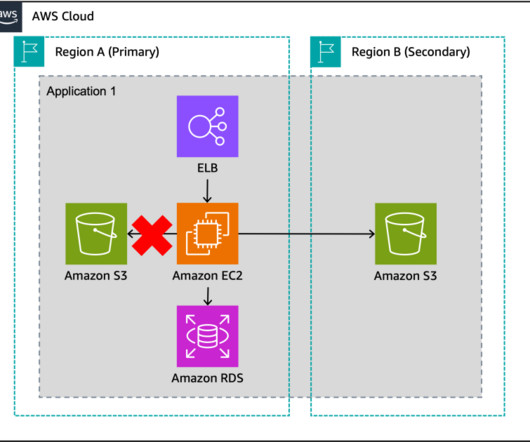
The question is, how will you ensure that any updates to your SQL database are captured not only in the active operational database but also in the secondary instances of the database residing in the backup AZs? In normal circumstances, the active SQL Server cluster node will reside in the same AZ as the primary storage node.
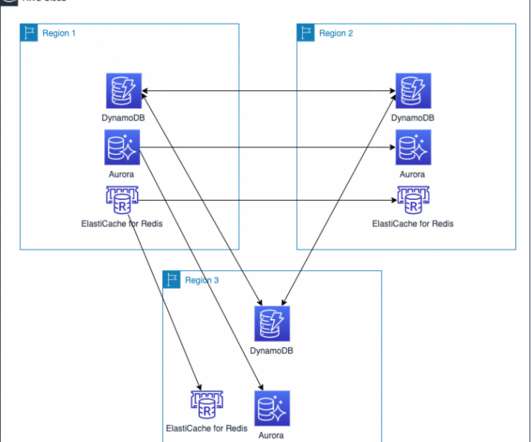
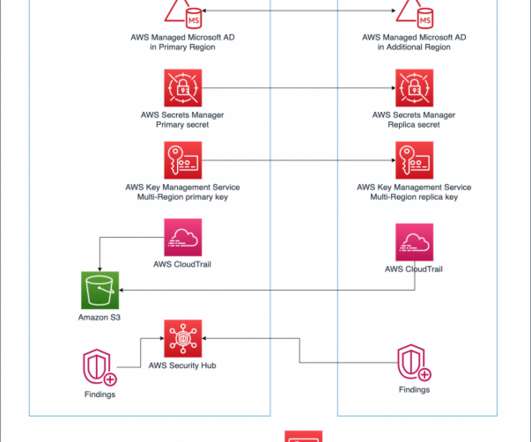
For workloads that use directory services, the AWS Directory Service for Microsoft Active Directory Enterprise Edition can be set up to automatically replicate directory data across Regions. AWS CloudTrail logs user activity and API usage. AWS Identity and Access Management (IAM) operates in a global context by default.
a manager of IT infrastructure and resiliency at Asian Paints, a consumer goods company, Zerto is essential for replication of virtual appliances, failover automation, and failback processes at their DR site. It also allowed us to preconfigure the boot sequence for a failover test or actual recovery.” For Amit B.,
In this blog post, we share a reference architecture that uses a multi-Region active/passive strategy to implement a hot standby strategy for disaster recovery (DR). With the multi-Region active/passive strategy, your workloads operate in primary and secondary Regions with full capacity. This keeps RTO and RPO low.
In this blog post, you will learn about two more active/passive strategies that enable your workload to recover from disaster events such as natural disasters, technical failures, or human actions. Then we explored the backup and restore strategy. Backups are necessary to enable you to get back to the last known good state.
Data protection is a broad field, encompassing backup and disaster recovery, data storage, business continuity, cybersecurity, endpoint management, data privacy, and data loss prevention. Acronis offers backup, disaster recovery, and secure file sync and share solutions. Note: Companies are listed in alphabetical order.
A great way to make sure it’s protected no matter what happens is through solutions like Pure Storage ® SafeMode ™, a high-performance data protection solution built into FlashArray™ that provides secure backup of all data. PX-Backup can continually sync two FlashBlade appliances at two different data centers for immediate failover.
The IDC study found that 79% of those surveyed activated a disaster response, 83% experienced data corruption from an attack, and nearly 60% experienced unrecoverable data. Backup to a Cloud Bucket. The Zerto for Kubernetes failover test workflow can help check that box. This means that applications are born protected.
Controller 1 is actively using those resources while controller 2 is in a standby configuration. You can update the software on controller 2, then failover so that it’s active. Then, you can update VM 1 with non-disruptive upgrades and within failover timeouts.
Instructions about how to use the plan end-to-end, from activation to de-activation phases. The DRP assumes that a disaster has disrupted your organization’s IT operations and/or infrastructure, and that certain measures need to be activated to return to normal operating conditions in the shortest possible time.
High-availability clusters: Configure failover clusters where VMs automatically migrate to a healthy server in case of hardware failure, minimizing service disruptions. Replication: Create backups of VMs on remote storage for disaster recovery purposes. Evaluate the level of support available for each option.
This includes developing and testing DR plans, implementing backup and recovery solutions, and providing training for staff on how to respond to a disaster. This eliminates the need for manual intervention and reduces the risk of human error when initiating a failover.
Read the Ebook Fast Recovery, without Data Loss Having identified Portworx as the foundation for its disaster recovery strategy, DXC Technology implemented an active/passive Metro-DR solution in two data centers that enables the immediate replication of any changes made to data or applications on the source cluster to the destination cluster.
Backup solutions like database and Amazon S3 replication can provide RPO of a few minutes at most, but RTO will vary considerably. Backup and restore (Tier 4). This pattern may incur more data loss depending on backup schedules. During failover, scale up resources and increase traffic to the Region. Pilot light (Tier 2).
In this feature, Zerto (HPE) ‘s Director of Technical Marketing Kevin Cole offers commentary on backup, disaster recovery, and cyber recovery and supporting the need for speed. Longer downtimes result in increased loss and recovering quickly should be top of mind. How do backup, disaster recovery, and cyber recovery differ?
Pure Storage vSphere Client Plugin: Pure Storage’s plugin for vSphere supports easy storage provisioning and management via Storage Policy Based Management (SPBM), provides orchestration for recovering VMs from SafeMode-protected snapshots, and can even manage replication of those snapshots to provide DR testing and orchestrated failover.
So IT leaders running production workloads on VMware on-premises can partner with the cloud provider to ensure a comparable VMware environment will be available as a failover destination in the cloud. are already defined and available before the cluster is needed for failover.
For this year’s datacenter failover exercise, 57 Tier 1 and 2 service applications where declared to be “impacted”. While the previous year’s test was more extensive, this year’s was limited to failover response testing and recovery of underlying information technology infrastructure only. The scale of these annual tests can vary.
Top Storage and Data Protection News for the Week of September 27, 2024 Cayosoft Secures Patent for Active Directory Recovery Solution Cayosoft Guardian Forest Recovery’s patented approach solves these issues by functioning as an AD resilience solution rather than a typical backup and recovery tool.
These seven features assist not just in recovering from a ransomware attack, but also in hardening systems and backups to prepare for and prevent ransomware attacks. Local systems and backups can be compromised, making remote recovery the only option left. More copies across recovery sites mean more recovery options when needed.
And it has the protective benefits of specialized cluster servers and regular backups to separate nodes or data centers. A basic approach is to use simple backups. Single-command failover. To minimize risk, orchestration steps for the entire environment stay the same during the test or in an actual failover event.
To counteract this challenge, Nissan Australia runs its manufacturing workloads on VMware in an active-active configuration across two data centers that leverage Pure Storage® FlashArray//X ™ with ActiveCluster ™ for seamless failovers. FlashBlade has also allowed Nissan Australia to consolidate its mainframe backups.
The question is, how will you ensure that any updates to your SQL database are captured not only in the active operational database but also in the secondary instances of the database residing in the backup AZs? In normal circumstances, the active SQL Server cluster node will reside in the same AZ as the primary storage node.
For example, HDDs are affordable for backup storage. For active applications, SSDs are commonly used since they offer faster IOPS. Backup devices and database storage might have more reads than a standard application server, so make sure you know the server’s purpose before determining IOPS importance.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content