This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
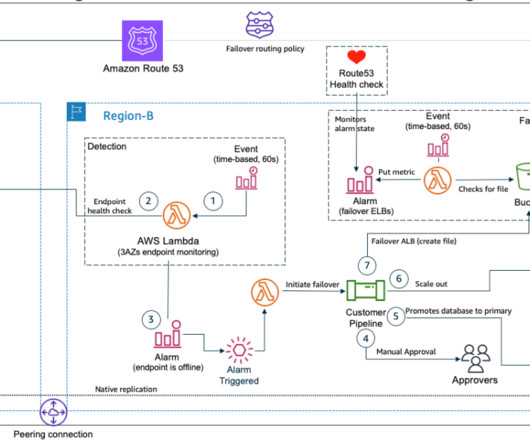
Therefore, if you’re designing a DR strategy to withstand events such as power outages, flooding, and other other localized disruptions, then using a Multi-AZ DR strategy within an AWS Region can provide the protection you need. Active/passive and active/active DR strategies. In Figure 3, we show how active/passive works.
One Pure Storage customer has done this to their original FlashArray FA-420 purchased in 2013 to include their controllers, bus architectures, and DirectFlash® Modules (DFMs) to become a FlashArray//X70 R3. Both controllers can receive I/O during normal operations, but the system only processes data through the active one.
The post also introduces a multi-site active/passive approach. The multi-site active/passive approach is best for customers who have business-critical workloads with higher availability requirements over other active/passive environments. You would just need to create the records and specify failover for the routing policy.
Using multiple Regions ensures resiliency in the most serious, widespread outages. Architecture overview. In our architecture, we use CloudWatch alarms to automate notifications of changes in health status. Disaster Recovery (DR) Architecture on AWS, Part II: Backup and Restore with Rapid Recovery. OpenSearch Service.
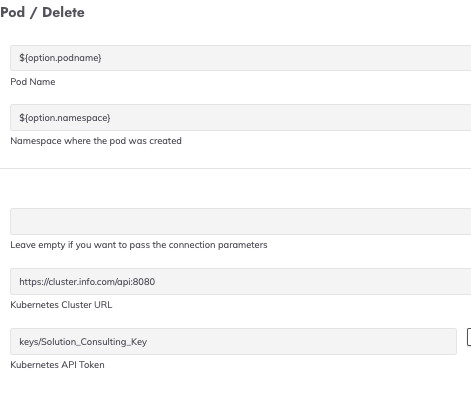
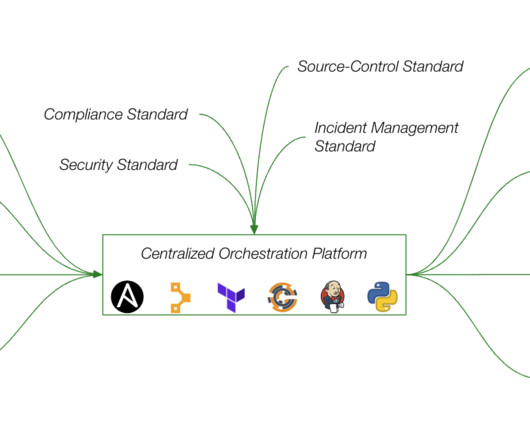
This can easily be extended to any activity within the Kubernetes ecosystem, and 23 plugins are available for tasks such as maintaining PVs, deploying services, grabbing logs, or running internal jobs. Any drift from this configuration can be corrected by reapplying the Terraform plan. Automated backups ensure that data is always recoverable.
Though ransomware has dominated conversations in the data protection sphere for quite some time, stories of recent outages due to this threat still circulate. The conversation delved into the technical design aspects of the vault, its architecture, and the rationale behind crucial decisions.
Pure Storage Architecture 101: Built-in Performance and Availability by Pure Storage Blog The world of technology has changed dramatically as IT organizations now face, more than ever, intense scrutiny on how they deliver technology services to the business. Each has its advantages and disadvantages.
As a result, businesses were on an ever-revolving turntable of purchasing new arrays, installing them, migrating data, juggling weekend outages, and managing months-long implementations. For our early customers, it has meant a decade without the hassles of migrations, storage refreshes, weekend outages, or application outages.
Remember, after an outage, every minute counts…. Jointly architectured by two of the industry’s most trusted companies, FlashRecover//S is designed specifically to deliver a powerful yet easy-to-use solution with multiple levels of built-in ransomware protection that can provide petabyte-scale recovery of data in just hours. .
Service outages ultimately frustrate customers, leading to churn and loss of trust. Continuously monitor system logs to detect unusual activity, such as failed login attempts or unauthorized data transfers. Endpoint detection and response tools monitor and respond to suspicious activities on devices within the network.
VDI deployment needs to be done on an architecture that is simple and can scale and integrate. You get the latest in compute, network, and storage components in a single integrated architecture that accelerates time to deployment, lowers overall IT costs, and reduces deployment risk. . Cache Assignment. Storage Pools. Front-end Ports.
There are two types of HA clustering configurations that are used to host an application: active-passive and active-active. The standby servers act as a ready-to-go copy of the application environment that can be a failover in case the primary (active) server becomes disconnected or is unable to service client requests.
Recovering your mission-critical workloads from outages is essential for business continuity and providing services to customers with little or no interruption. Depending on the RPO and RTO of the mission-critical workload, the requirement for disaster recovery ranges from simple backup and restore, to multi-site, active-active, setup.
These capabilities facilitate the automation of moving critical data to online and offline storage, and creating comprehensive strategies for valuing, cataloging, and protecting data from application errors, user errors, malware, virus attacks, outages, machine failure, and other disruptions. Note: Companies are listed in alphabetical order.
The collapse of the building structurally compromised a nearby law office, an architectural firm had water damage, and surrounding buildings had smoke and broken window damage. The investigation and cleanup activities forced changes in business operations. The damage was not limited to this building.
The collapse of the building structurally compromised a nearby law office, an architectural firm had water damage, and surrounding buildings had smoke and broken window damage. The investigation and cleanup activities forced changes in business operations. The damage was not limited to this building.
If there are any issues with the fulfillment of our performance or capacity obligations, you can trust Pure to resolve this with our best-in-class NPS score of 83+ and our Evergreen™ and Evergreen architecture. Provider will notify Customer when OnDemand Capacity requires expansion in order to agree upon required expansion activities”.
Consider engaging in a discussion with the CISO about the benefits of tiered security architectures and “ data bunkers ,” which can help retain large amounts of data and make it available immediately. The planning should also include critical infrastructure such as Active Directory and DNS.
patient records, student records, and information about active law enforcement cases), and they know where to post it to do the most damage. . If hackers take out your organization’s active directory, DNS, or other core services, or lock you out of your infrastructure entirely, you’re at their mercy without available recovery points.
The recent global outage reminds us that identifying issues and their impact radius is just the first part of a lengthy process to remediation. It spans a wide range of activities, from incident response and reliability management to provisioning and reporting. See the diagram below for a sample architecture.
Top Storage and Data Protection News for the Week of September 27, 2024 Cayosoft Secures Patent for Active Directory Recovery Solution Cayosoft Guardian Forest Recovery’s patented approach solves these issues by functioning as an AD resilience solution rather than a typical backup and recovery tool.
However, because setting it up involves rebuilding much of the organization’s network security architecture, implementing it is a serious burden and a major project, one that typically takes multiple years. Once it’s in place, Zero Trust is highly secure and very convenient.
Since then, so much more value has been added to our all-flash platform with innovative releases such as ActiveCluster ™ (active-active synchronous replication), FlashArray//X ™ (the first enterprise-class all-NVMe FlashArray™), ActiveDR ™ continuous replication , and FlashArray//XL ™.
Each service in a microservice architecture, for example, uses configuration metadata to register itself and initialize. If you’re using infrastructure as a service (IaaS), constantly check and monitor your configurations, and be sure to employ the same monitoring of suspicious activity as you do on-prem. .
Maybe you even want to tweak the designs of your alerts so that you don’t need to do as much correction after-the-fact, and during an active incident, at all. We might think in terms of thresholds where a service can budget for a given amount of latency or outage time, but it’s dependent services might have stricter requirements.
The IDC study found that 79% of those surveyed activated a disaster response, 83% experienced data corruption from an attack, and nearly 60% experienced unrecoverable data. As more enterprises adopt containers and Kubernetes architectures for their applications, the reliance on microservices requires a solid data protection strategy.
The folks over at XtremIO have been busy this holiday season, penning a nearly 2,000-word blog to make the argument for their scale-out architecture vs. dual-controller architectures. never having to ask for an outage window). We call this non-disruptive operations.
The recent global outage reminds us that identifying issues and their impact radius is just the first part of a lengthy process to remediation. It spans a wide range of activities, from incident response and reliability management to provisioning and reporting. See the diagram below for a sample architecture.
Any data that has been identified as valuable and essential to the organization should also be protected with proactive security measures such as Cyberstorage that can actively defend both primary and backup copies from theft.” However, backups fail to provide protection from data theft with no chance of recovery.
A recent Pure Storage survey found that 69% of organizations consider recovering from a cyber event to be fundamentally different from recovering from a “traditional” outage or disaster. In short, you need a resilient architecture that lets you recover quickly. Learn more about how Pure Storage helps you build a resilient architecture.
For example, many architectures on AWS, even those that split workloads into multiple availability zones, have one central data lake or bucket. The biggest myths in AWS architecture are often related to resilience. While business continuity is about emergency preparedness, data resiliency is an ongoing, 24/7 activity.
Pure offers additional architectural guidance and best practices for deploying MySQL workloads on VMware in the new guide, “ Running MySQL Workloads on VMware vSphere with FlashArray Storage.” This component determines which array will continue data services should a power outage occur. Active/active clustered array pairs.
You need to ensure the incident is moving forward, the right teams are working on it, and stakeholders and customers are receiving accurate and timely updates about the outage. However, customers aren’t interested in how many teams you have or the complexity of your architecture. This is a story we hear often.
Technology The finance sector is known for its outdated legacy system architecture that cannot handle increasing data volume. Spending System outages at financial institutions cost an average of $9.3 Heres why banks and financial institutions need managed IT to keep customers satisfied. million per hour of downtime.
Typically, this will involve the use of redundant systems, disaster recovery as a service , and resilient data storage architectures designed to support rapid and complete recovery. These activities help identify gaps in the plan and provide practice for the team responsible for implementing it in a real disaster.
Typically, this will involve the use of redundant systems, disaster recovery as a service , and resilient data storage architectures designed to support rapid and complete recovery. These activities help identify gaps in the plan and provide practice for the team responsible for implementing it in a real disaster.
A single point of failure, slow recovery from outages, and the increasing complexity of modern data environments demand a re-evaluation of storage strategies. With data breaches, cyberattacks and human error contributing to increased business outages, its essential to adopt a comprehensive backup strategy built on zero trust principles.
Utility companies can do more proactive maintenance to avoid downtime and outages. Spatial data drives the activities of these robots. The modern architecture of Pure Storage ® FlashBlade ® lets you implement a UFFO storage platform without the challenges associated with retrofitting legacy storage solutions. .
Read more: 5 Ransomware Recovery Steps to Take After a Breach Assess Your Risks and Cybersecurity Needs As with all threats—cyber threats or natural disasters—the key is building resiliency into your architecture. In general, there’s not much that can be done to prevent a natural disaster.
Application: AI-driven surveillance enhances facility security by detecting unusual activities, intruders, or potential security threats. Environmental Monitoring for Critical Infrastructure: How it Works: IoT sensors monitor environmental conditions such as temperature, humidity, and seismic activity around critical infrastructure.
Mitigating supply chain risk After widespread coverage, the CrowdStrike outage from 19 July 2024 hardly needs an introduction. The outage was caused by a bad security update rolled out by CrowdStrike. Without question, this is one of the most expensive IT outages to date, with significant global impact. million Windows devices.
In 2024, it will be crucial to optimize the transparency afforded by these regulations, and by dragging cybercriminals out into the open, authorities can more effectively curtail their illicit activity.” If the AI detects unusual activity, it can respond autonomously to increase their level of protection.
At this point, Route 53 will redirect traffic to the ALB in the secondary Region, becoming the new active endpoint. At this point, the ALB in the primary Region becomes active and failback completes successfully. This design showcases the company’s ability to tailor their architecture to their specific requirements.
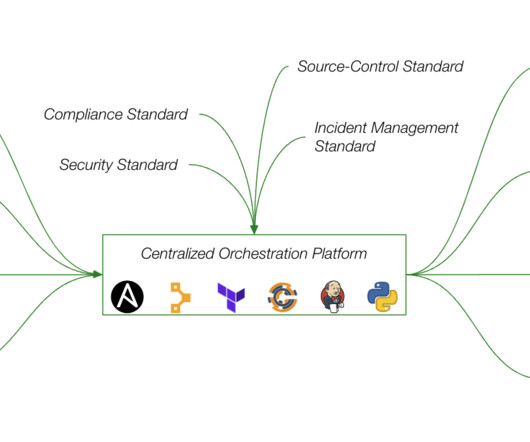
Building Operational Cyber Resilience using the Pure 5//S Principles by Pure Storage Blog Summary The five key pillars of a cyber resilient architecture are: Speed, Security, Simplicity, Scale, and Sustainability. It requires an architecture model that takes into account arbitrary scale of the system: storage, compute, and network resources.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.












































Let's personalize your content