This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
You can use these fault boundaries to build multi-Region applications that consist of independent, fault-isolated replicas in each Region that limit shared fate scenarios. However, applications typically don’t operate in isolation; consider both the components you will use and their dependencies as part of your failover strategy.
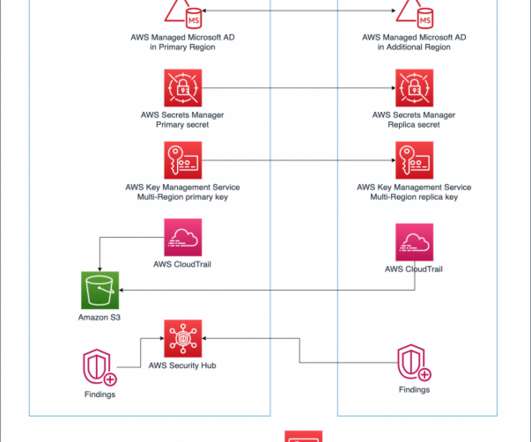
Building a multi-Region application requires lots of preparation and work. In this 3-part blog series, we’ll explore AWS services with features to assist you in building multi-Region applications. Finally, in Part 3, we’ll look at the application and management layers. AWS CloudTrail logs user activity and API usage.
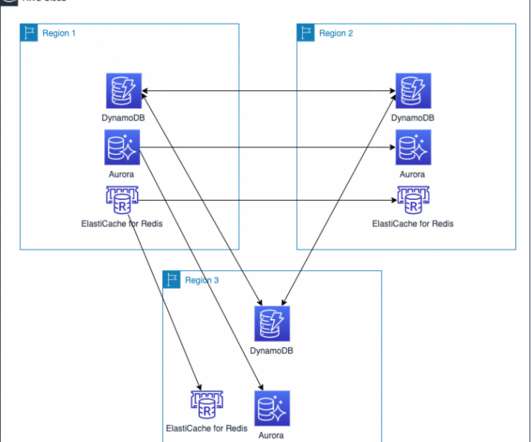
In Part 1 of this blog series, we looked at how to use AWS compute, networking, and security services to create a foundation for a multi-Region application. Data is at the center of many applications. For this reason, data consistency must be considered when building a multi-Region application.
The post also introduces a multi-site active/passive approach. The multi-site active/passive approach is best for customers who have business-critical workloads with higher availability requirements over other active/passive environments. You would just need to create the records and specify failover for the routing policy.
Failover vs. Failback: What’s the Difference? by Pure Storage Blog A key distinction in the realm of disaster recovery is the one between failover and failback. In this article, we’ll develop a baseline understanding of what failover and failback are. What Is Failover? Their effects, however, couldn’t be more different.
Failover vs. Failback: What’s the Difference? by Pure Storage Blog A key distinction in the realm of disaster recovery is the one between failover and failback. In this article, we’ll develop a baseline understanding of what failover and failback are. What Is Failover? Their effects, however, couldn’t be more different.
Growing in both volume and severity, malicious actors are finding increasingly sophisticated methods of targeting the vulnerability of applications. Victims are either forced to pay the ransom or face total loss of business-critical applications. by protecting any application using continuous data protection (CDP).
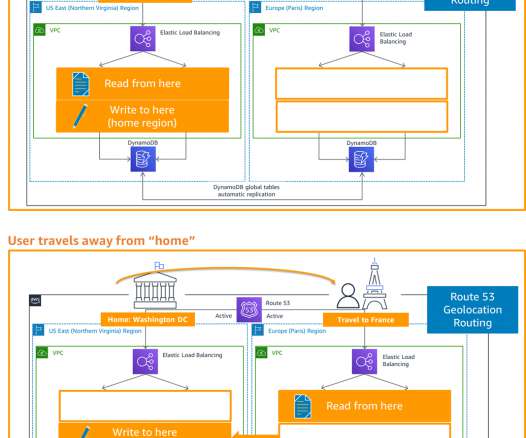
My subsequent posts shared details on the backup and restore , pilot light, and warm standby active/passive strategies. In this post, you’ll learn how to implement an active/active strategy to run your workload and serve requests in two or more distinct sites. DR strategies: Multi-site active/active. DR strategies.
Active-active vs. Active-passive: Decoding High-availability Configurations for Massive Data Networks by Pure Storage Blog Configuring high availability on massive data networks demands precision and understanding. Now, let’s dive into Active-active vs. Active-passive. What Is Active-active?
Customers only pay for resources when needed, such as during a failover or DR testing. Automation and orchestration: Many cloud-based DR solutions offer automated failover and failback, reducing downtime and simplifying disaster recovery processes. Replication log latency is important for application performance. Azure or AWS).
It’s easy to set up and usually the SAP application or SAP BASIS team does the configuration and controls the failovers. . First, it can synchronously replicate at the memory layer, so, in the event of a failover, there’s no waiting for memory loads to happen before the system can be considered up.
When you deploy mission-critical applications, you must ensure that your applications and data are resilient to single points of failure. Organizations are increasingly adopting a multicloud strategy—placing applications and data in two or more clouds in addition to an on-premises environment.
Now they need to access data using an internal business application. application username and password) to authenticate into the software and access data. The biggest advantage of VPN is that it’s easy to implement and many solutions work directly with Active Directory or LDAP. Applications also validate their authorization.
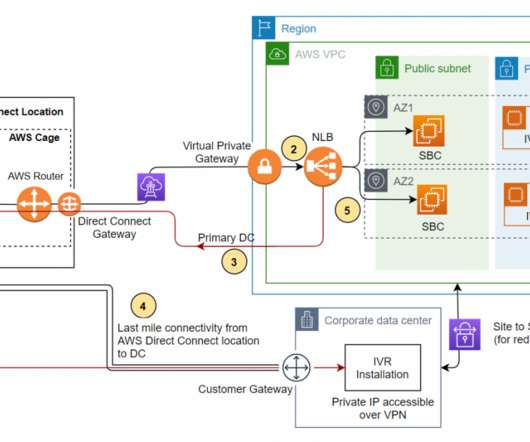
These are backup and restore, active/passive (pilot light or warm standby), or active/active. In other cases, the customer may want to use their home developed or third-party contact center application. Based on these health checks, the NLB will do the routing and the failover. Disaster recovery (DR) options.
No application is safe from ransomware. The IDC study found that 79% of those surveyed activated a disaster response, 83% experienced data corruption from an attack, and nearly 60% experienced unrecoverable data. While the benefits may seem great in theory, refactored applications must first overcome unexpected challenges.
AWS makes it easy to configure the compute and storage resources needed to meet your application and performance demands. The question is, how will you ensure that any updates to your SQL database are captured not only in the active operational database but also in the secondary instances of the database residing in the backup AZs?
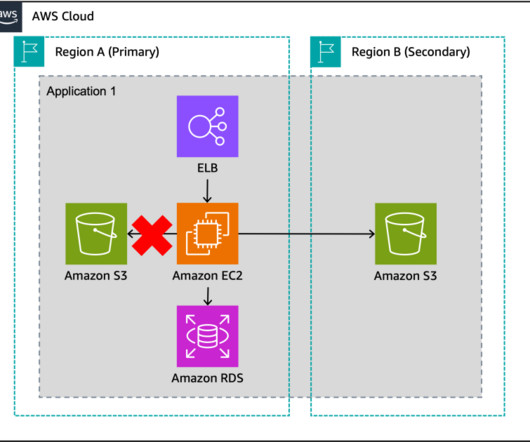
Using a backup and restore strategy will safeguard applications and data against large-scale events as a cost-effective solution, but will result in longer downtimes and greater loss of data in the event of a disaster as compared to other strategies as shown in Figure 1. The application diagram presented in Figures 2.1
In this blog post, we share a reference architecture that uses a multi-Region active/passive strategy to implement a hot standby strategy for disaster recovery (DR). With the multi-Region active/passive strategy, your workloads operate in primary and secondary Regions with full capacity. This keeps RTO and RPO low.
Even with the higher speed capacity, an SSD has its disadvantages over an HDD, depending on your application. SSDs aren’t typically used for long-term backups, so they’re built for both but are typically used in speed-driven applications. Applications that require fast data transfers take advantage of SSDs the most.
Episode Summary: Gamification is the application of game-design elements and game principles in non-game contexts. But what he’s especially good at is developing ways to gamify business continuity activities. Gamification is the application of game-design elements and game principles in non-game contexts.
DR tries to minimize the impact a disaster has on applications, restoring them to a usable state as quickly as possible. SRE, on the other hand, is a discipline (and job title for many) that applies engineering practices to operations to improve the reliability and availability of the infrastructure that hosts applications.
High-availability clusters: Configure failover clusters where VMs automatically migrate to a healthy server in case of hardware failure, minimizing service disruptions. Key features of Nutanix AHV: Storage: Nutanix has integrated storage that distributes data across multiple disks, making it better for failover and data integrity.
One-to-many replication allows you to replicate data from a single source to multiple (up to three) target environments, providing a flexible and efficient way to protect your data and applications. In addition, virtual protection groups also enable various recovery options for different VMs, applications, or files.
Here, we delve into HA and DR, the dynamic duo of application resilience. High Availability is the ability of an application to continue to serve clients who are requesting access to its services. There are two types of HA clustering configurations that are used to host an application: active-passive and active-active.
a manager of IT infrastructure and resiliency at Asian Paints, a consumer goods company, Zerto is essential for replication of virtual appliances, failover automation, and failback processes at their DR site. It also allowed us to preconfigure the boot sequence for a failover test or actual recovery.” For Amit B.,
Instructions about how to use the plan end-to-end, from activation to de-activation phases. References to Runbooks detailing all applicable procedures step-by-step, with checklists and flow diagrams. Note that the DRP can be invoked without triggering the activation of the BCP. The purpose and scope of the BCP.
Modernizing Outdated Infrastructure Wolthuizen is responsible for the company’s Managed Container Services offering, which enables rapid application deployment in Kubernetes container environments on any cloud, regardless of the underlying infrastructure. CDP is widely used by DXC Technology’s government clients in Italy.
A strong cyber recovery plan—sometimes referred to as a “cybersecurity disaster recovery plan”— includes advanced tools such as a “ cyber vault ,” which isolates critical data and applications from the primary system to protect them from cyber threats. Backup Disaster recovery encompasses a broader approach than backup alone.
Life-supporting applications such as those used by the City of New Orleans’s IT department must always be on. It maintains application performance with continuous replication and near-zero RPO/RTO. It’s eminently important for them to have a scenario where they can test failoveractively without disrupting these services. .
For software replication with Always On availability groups across regions in Microsoft SQL Server 2022, the following benefits can be realized: Volume snapshots and asynchronous replication can be used to ensure that, after failover, disaster recovery posture can be regained rapidly. Seeding and reseeding times can be drastically minimized.
But having control when it’s spread across hundreds of different applications both internal and external and across various cloud platforms is a whole other matter. . The problem is that most businesses don’t know how to protect their containerized applications. According to Cybersecurity Insiders’ 2022 Cloud Security Report : .
For this year’s datacenter failover exercise, 57 Tier 1 and 2 service applications where declared to be “impacted”. While the previous year’s test was more extensive, this year’s was limited to failover response testing and recovery of underlying information technology infrastructure only.
In Part I of this two-part blog , we outlined best practices to consider when building resilient applications in hybrid on-premises/cloud environments. In a DR scenario, recover data and deploy your application. Run scaled-down versions of applications in a second Region and scale up for a DR scenario. Active-active (Tier 1).
Equally important is to look at throughput (units of data per second)—how data is actually delivered to the arrays in support of real-world application performance. For activeapplications, SSDs are commonly used since they offer faster IOPS. However, looking at IOPS is only half the equation. So in short, you should use both.
These capabilities facilitate the automation of moving critical data to online and offline storage, and creating comprehensive strategies for valuing, cataloging, and protecting data from application errors, user errors, malware, virus attacks, outages, machine failure, and other disruptions. Note: Companies are listed in alphabetical order.
So IT leaders running production workloads on VMware on-premises can partner with the cloud provider to ensure a comparable VMware environment will be available as a failover destination in the cloud. are already defined and available before the cluster is needed for failover.
Backup and recovery technology is also steadily advancing; as detailed in Gartner’s Magic Quadrant for Data Center Backup and Recovery Solutions, “by 2022, 40 percent of organizations will replace their backup applications from what they deployed at the beginning of 2018.”
And many have chosen MySQL for their production environments for a variety of use cases, including as a relational database or as a component of the LAMP web application stack. But, because database applications like MySQL can be particularly demanding, it’s important to ensure the right resources are allocated to each virtual machine.
Any data that has been identified as valuable and essential to the organization should also be protected with proactive security measures such as Cyberstorage that can actively defend both primary and backup copies from theft.” The result is that large sections of corporate datasets are now created by SaaS applications.
AWS makes it easy to configure the compute and storage resources needed to meet your application and performance demands. The question is, how will you ensure that any updates to your SQL database are captured not only in the active operational database but also in the secondary instances of the database residing in the backup AZs?
On-prem data sources have the powerful advantage (for design, development, and deployment of enterprise analytics applications) of low-latency data delivery. It has been republished with the author’s credit and consent. In addition to low latency, there are also other system features (i.e.,
You also need various applications to connect with your customers, vendors, and employees. This means that instead of constantly worrying about IT problems, you and your employees can focus on core business activities. If you own a small- or mid-sized business (SMB), you know that IT is essential to your organization's success.
The cloud providers have no knowledge of your applications or their KPIs. Others will weigh the cost of a migration or failover, and some will have already done so by the time the rest of us notice there’s an issue. What can we bring from our experiences handling our own incidents? Many teams will have to sit and wait out the problem.
Immutable centralized incident record : PagerDuty provides a time-stamped log of all activities and resolution steps relating to an incident. Alternatively, firms could manually disable a machine or application or create a PagerDuty test incident to trigger an outage and then practice their response procedures.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













































Let's personalize your content