This site uses cookies to improve your experience. To help us insure we adhere to various privacy regulations, please select your country/region of residence. If you do not select a country, we will assume you are from the United States. Select your Cookie Settings or view our Privacy Policy and Terms of Use.
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Used for the proper function of the website
Used for monitoring website traffic and interactions
Cookie Settings
Cookies and similar technologies are used on this website for proper function of the website, for tracking performance analytics and for marketing purposes. We and some of our third-party providers may use cookie data for various purposes. Please review the cookie settings below and choose your preference.
Strictly Necessary: Used for the proper function of the website
Performance/Analytics: Used for monitoring website traffic and interactions
Welcome to the third post of a multi-part series that addresses disasterrecovery (DR) strategies with the use of AWS-managed services to align with customer requirements of performance, cost, and compliance. You would just need to create the records and specify failover for the routing policy.
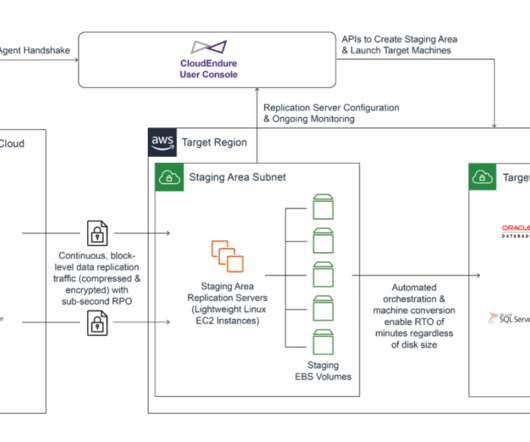
When designing a DisasterRecovery plan, one of the main questions we are asked is how Microsoft Active Directory will be handled during a test or failover scenario. You can instruct CloudEndure DisasterRecovery to automatically launch thousands of your machines in their fully provisioned state in minutes.
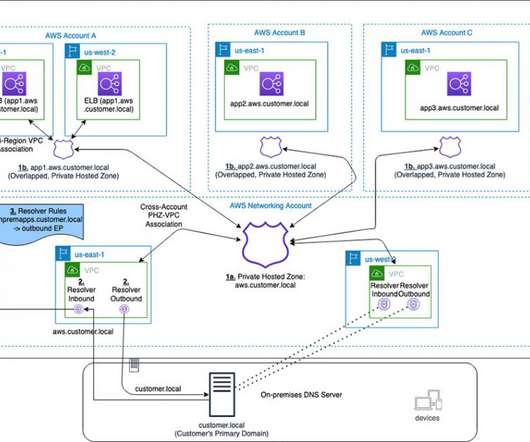
This post was co-written by Anandprasanna Gaitonde, AWS Solutions Architect and John Bickle, Senior Technical AccountManager, AWS Enterprise Support. Many AWS customers have internal business applications spread over multiple AWS accounts and on-premises to support different business units. Introduction. Considerations.
Minimum business continuity for failover. Building disasterrecovery (DR) strategies into your system requires you to work backwards from recovery point objective (RPO) and recovery time objective (RTO) requirements. Centralized cross-accountmanagement with Cross-Region copy using AWS Backup.
Others will weigh the cost of a migration or failover, and some will have already done so by the time the rest of us notice there’s an issue. Managing vendor relationships often falls to a procurement, finance, or legal team. Email addresses or contact information for your accountmanagers and the vendor’s support team.
Others will weigh the cost of a migration or failover, and some will have already done so by the time the rest of us notice there’s an issue. Managing vendor relationships often falls to a procurement, finance, or legal team. Email addresses or contact information for your accountmanagers and the vendor’s support team.
vSphere high availability (HA) and disasterrecovery (DR): VMware offers built-in high availability and disasterrecovery features, ensuring that critical workloads can quickly recover from failures with minimal downtime. Its flexible architecture allows for both on-premises and cloud integration.
We organize all of the trending information in your field so you don't have to. Join 25,000+ users and stay up to date on the latest articles your peers are reading.
You know about us, now we want to get to know you!
Let's personalize your content
Let's get even more personalized
We recognize your account from another site in our network, please click 'Send Email' below to continue with verifying your account and setting a password.













Let's personalize your content